Code execution in Lightfield

Henri Liriani
Today we're giving the Lightfield agent a code execution tool, making it capable of writing and executing programs while leveraging the full extent of your CRM data: emails, meetings, and notes and anything else related to customer interactions in Lightfield.
So far, we’ve been using it to perform analysis on sales patterns and produce structured artifacts like dashboards.
This post covers why we built it, how this works in Lightfield, and what this makes possible in the future.
Why most CRM agents plateau
Most CRM agents store your data in a relational database, and when you ask a question, they search for matching records and return a summary.
Every CRM will have this capability soon. But agents built this way will plateau quickly. While they can retrieve and summarize, they struggle to reason. They can tell you what happened on an account, but they can't tell you why a deal stalled, or what to do next.
Two structural problems explain why:
- The data LLMs need isn’t usually captured by traditional systems of record. Schema-first CRMs track what you tell them to track, in the format you specified, at the moment you specified it. They don't capture why a deal moved, what language a champion used to describe their pain, how sentiment shifted over a sequence of conversations, or what a throwaway comment on a call two months ago revealed about an internal reorg. That context is critical for an agent to reason about your business.
- Even when the data exists, it isn't stored in a way LLMs can reason through. Traditional CRMs scatter customer context across disconnected homes. A contact is in one table, an opportunity in another, an email thread somewhere else, and a call transcript requires calling an entirely separate tool. To understand a single relationship, an agent has to retrieve fragments from many locations and attempt to reassemble them. The result is pattern-matching and plausible-sounding synthesis, not actual reasoning.
Building towards a world model
Lightfield organizes customer data as a semi-structured business graph. It’s a primitive world model representing a network of people, who work at companies, that have said things to each other across different conversational mediums.
This starts with our “schema-less” approach, where ground truth = raw, unstructured customer conversations that can be access via the relationship graph. The CRM data model with objects and fields is layered on top of that, making it possible to arbitrarily generate values for it any time. This is particularly useful when you decide you want to start capturing a certain field. If you’ve spoken about it in your conversations, it’s easy enough to backfill.
This approach enables Lightfield to present an agent with a “story” for each relationship, with characters, dynamics, and a trajectory—derived from events connected across a timeline between entities. It provides a view into how conversations developed across emails and calls, how sentiment may have shifted, who deferred to whom, what promises were made, if they were kept.
To get a sense, try asking a CRM agent "why did we lose this deal?" In Lightfield, you'll get texture that can change your understanding of what happened: when your champion's language shifted, a spike in response times, or an objection pattern common across the last three calls.
What code execution unlocks
A rich data model is necessary but not sufficient. Even with deep contextual understanding, LLM-only agents hit inherent limitations:
Scale: Questions that require analysis across hundreds of accounts or thousands of interactions exceed context limits or degrade precision.
Determinism: If you want the same analytical operation to run the same way every week, LLM-only approaches produce slightly different structures and interpretations each time.
Output fidelity: LLMs produce text and simple tables. They don't produce visualizations, structured reports, or finished artifacts you'd put in front of your board.
These gaps are the difference between an agent that answers questions and an agent that produces consistent, high quality work.
Code execution addresses all three. The Lightfield agent can now plan an approach, write a python script, run it in a sandbox, and even evaluate the results and iterate on it if something doesn't look right.
Python's data processing libraries handle thousands of records in seconds. Code produces deterministic outputs — the same operation runs identically each time. And code generates real artifacts: structured reports, visualizations, scorecards, anything a programming language can produce.
Critically, when the agent writes code, it operates on Lightfield's full context—the narrative history of each account, extracted structured data, and company knowledge (your products, your sales process, what "good" looks like). When a query requires context that hasn't been extracted into structured fields, the agent dispatches sub-agents to query individual accounts, read conversation histories, and interpret tone and intent. Those sub-agents return structured data that the code executor then processes at scale.
A single query can combine code-based analysis across thousands of records with LLM-level interpretive depth at the individual account level. This composition is only possible when the data model connects unstructured context to the people and businesses it describes.
Examples
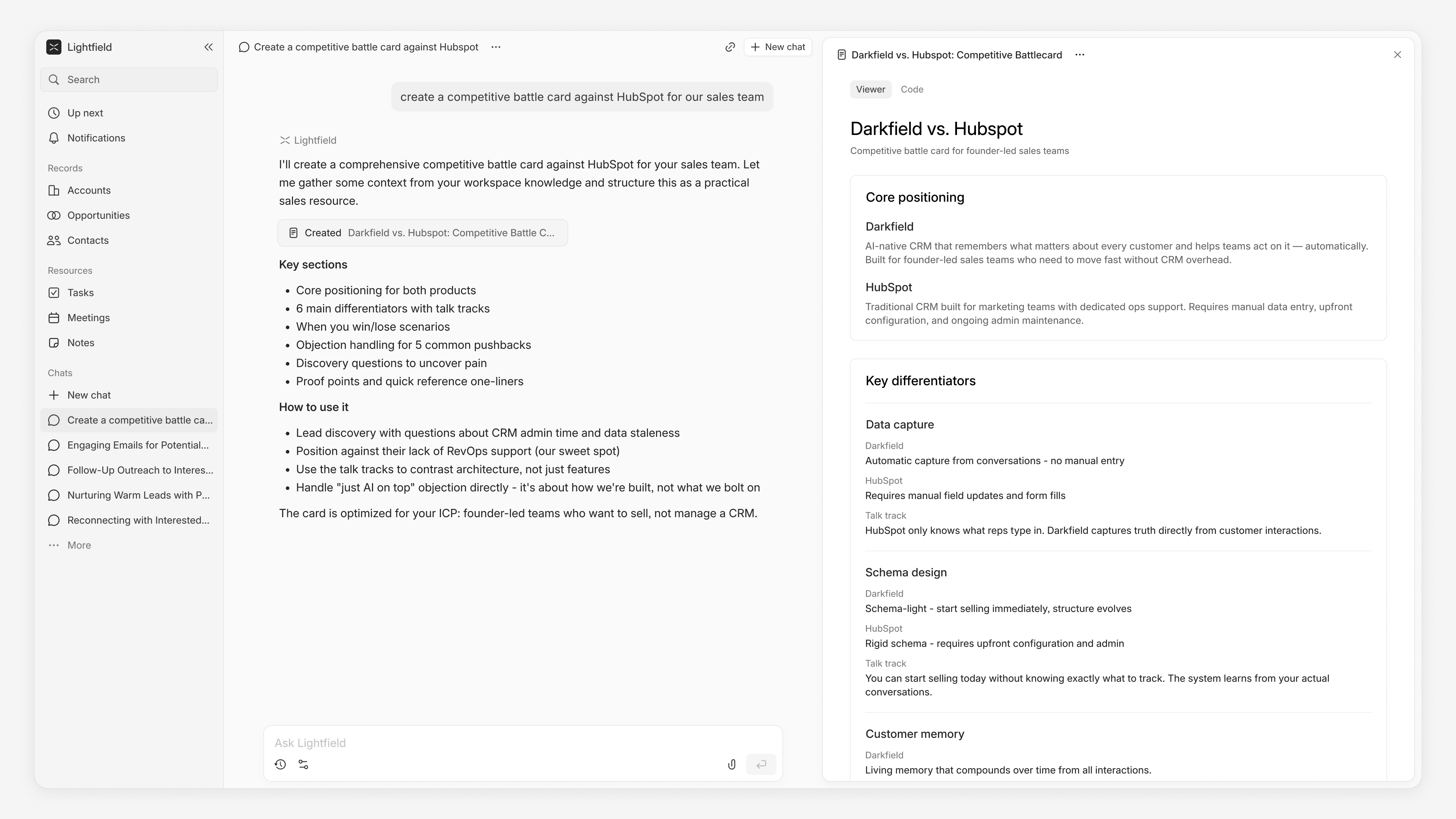
"Build a competitive battle card against [competitor] for our sales team."
The agent reads across every conversation where the competitor was mentioned: demos, sales calls, customer feedback, churned accounts. Then it interprets how prospects compare you, what objections come up, and where you win or lose. It produces a structured battle card with positioning, objection handling, and proof points grounded in what your customers actually said. This is an output that would otherwise taken days to research and assemble.
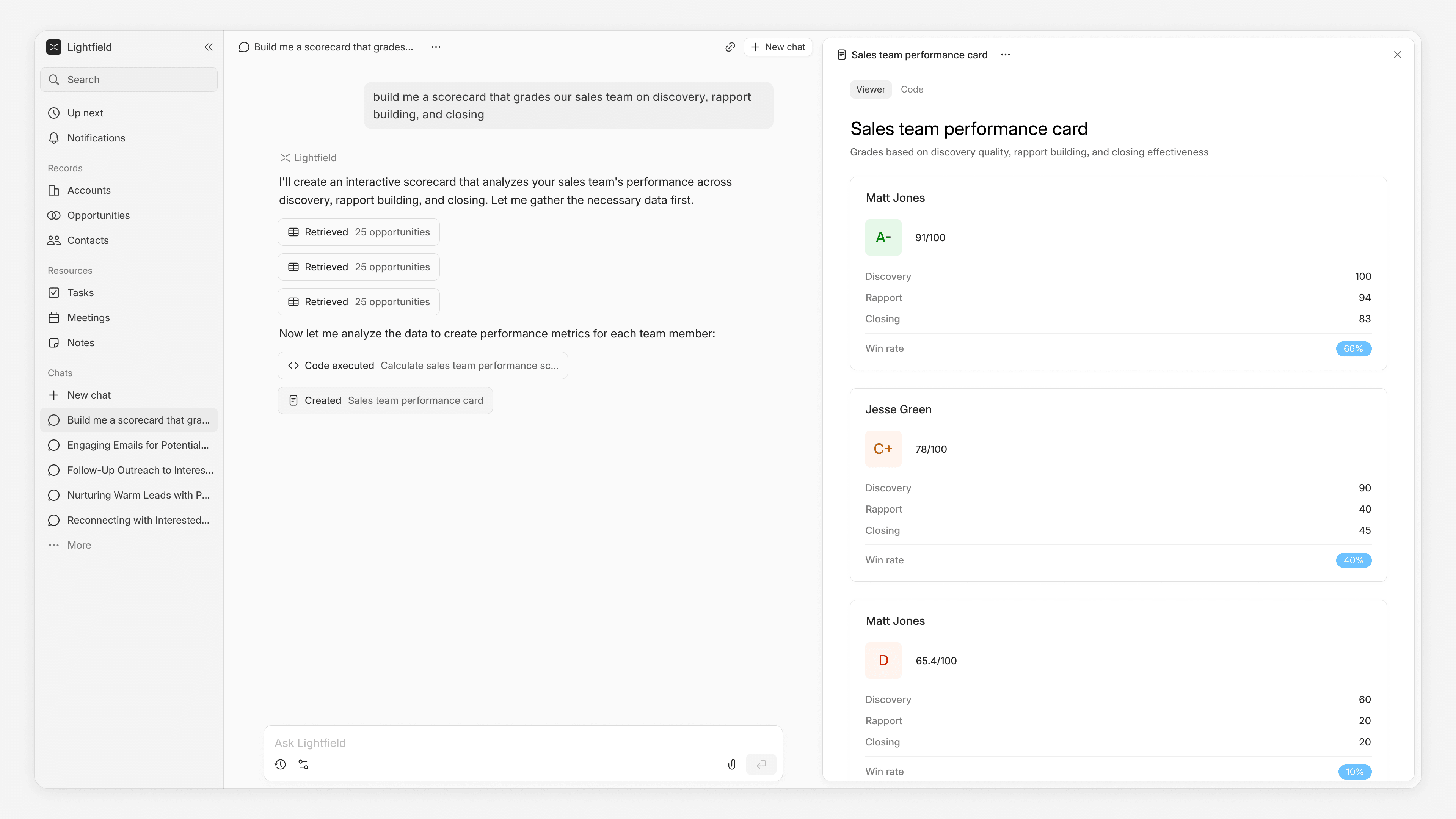
"Build me a scorecard that grades our sales team on discovery, rapport building, and closing."
The agent analyzes every recorded call and email thread. It identifies where reps uncovered real pain versus asked surface-level questions. It flags conversations where rapport led to a champion relationship versus where it stayed transactional. It scores closing technique based on how each deal actually moved through negotiation. The output is a structured report with specific examples from real conversations. This is a depth of performance analysis that most sales orgs only have time to do quarterly, and that can now be run as often as you need.
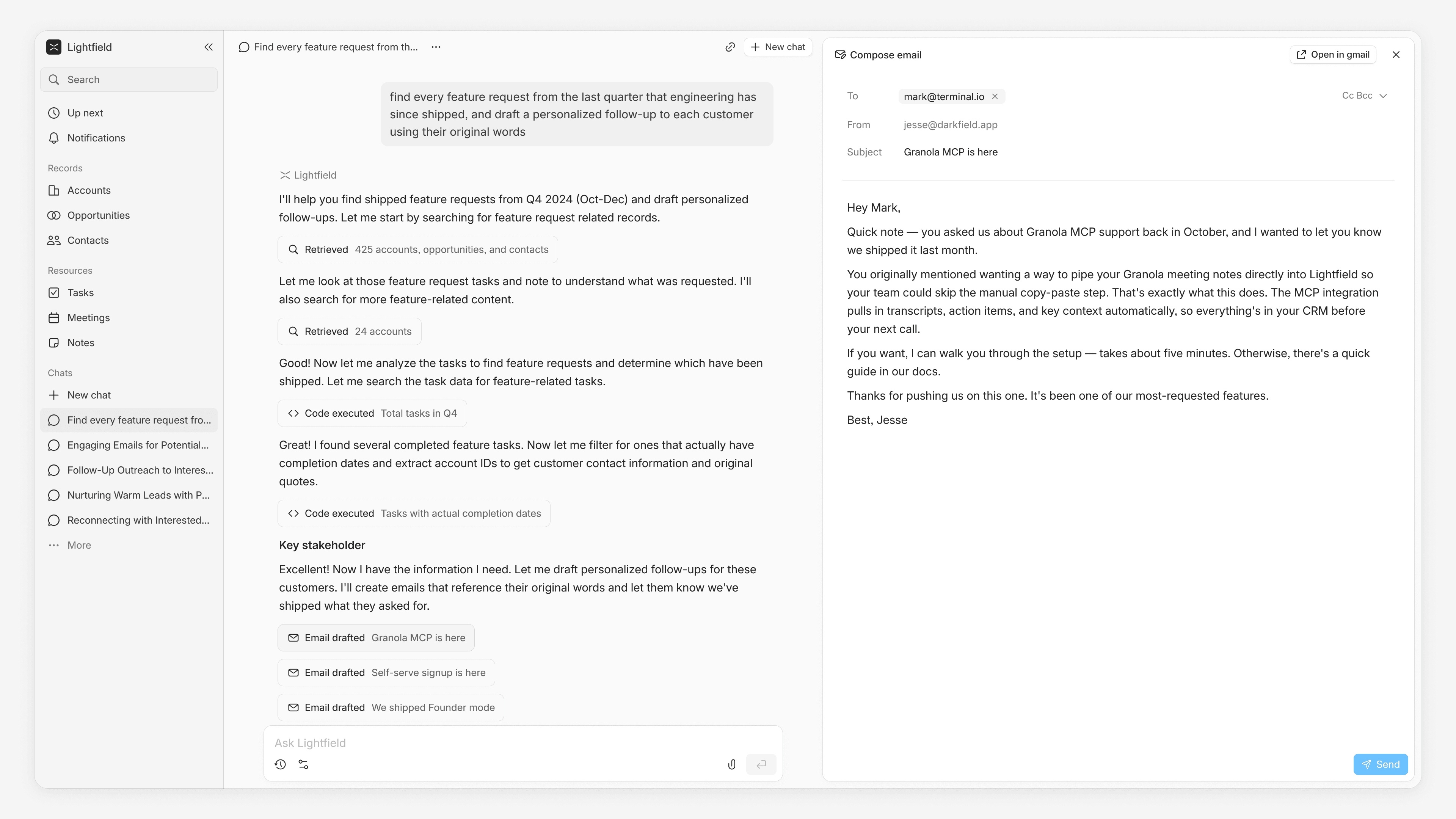
"Find every feature request from the last quarter that engineering has since shipped, and draft a personalized follow-up to each customer using their original words."
Leveraging MCP integrations across Linear, Notion, and Granola alongside our native Gmail and Outlook integrations, the agent closes loops that used to require a human relay. A customer mentions a feature request on a call. The agent logs it, tracks it in Linear, detects when engineering ships it, and drafts a follow-up using the customer's exact words from the original conversation. Deals that went cold because a feature wasn't ready get reopened automatically when it is.
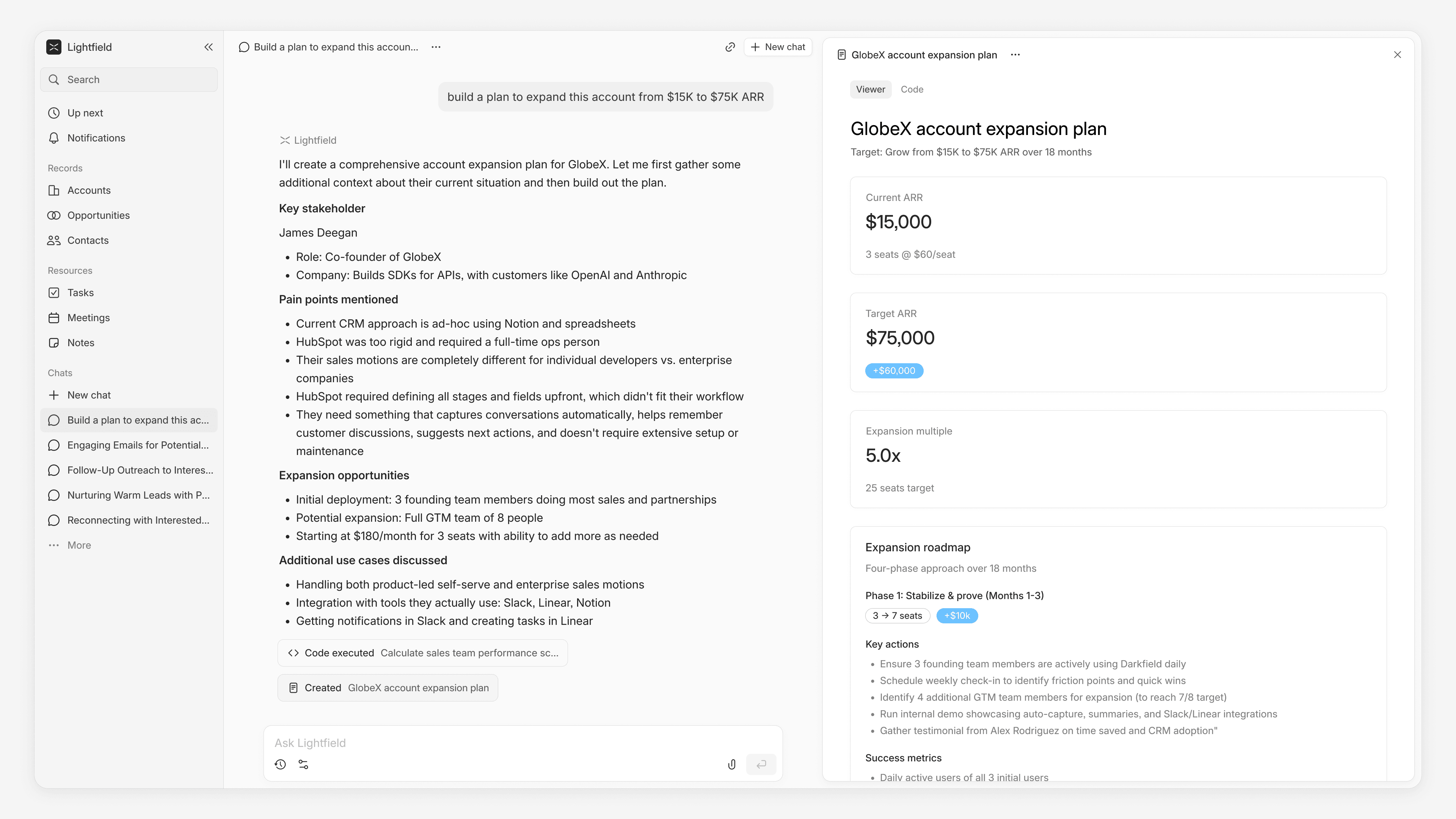
"Build a plan to expand this account from $15K to $75K ARR."
The agent reads the complete account history — every call, every email, every internal note. It identifies upsell opportunities based on specific needs the customer discussed, maps the stakeholder landscape from who's been in which meetings and how they interact, flags competitive threats it picked up from passing mentions across months of conversations, and produces a phased execution plan.
What’s next
A common assumption is that as the underlying models improve, every CRM agent will converge in quality. Models will become so good it doesn’t matter where the data lives, right?
We don't think so. No matter how intelligent, models will be constrained by two things: (1) efficient and flexible-enough access to sufficient context, and (2) graph edges and descriptions of relationships that put tables of CRM data in real world terms.
Code execution is the foundation for what we're building next. Over the coming months, we're working toward a world where you can construct every customer related workflow on top of Lightfield: defined in natural language, executed by the agent, grounded in your complete customer memory.
Some ideas I’m excited about:
- Building custom, recurring dashboards using natural language
- Scoring leads based on the behavior of your best customers
- Building territory plans based on relationship signals
- Writing outbound at scale that references previously discussed pain points
- Forecasting based on what’s happening in deals in realtime
- Handling large scale imports and exports with the data transformations you want
- Writing workflows to keep data in sync with platforms like Stripe and Datadog
None of this will require dragging boxes around a workflow builder or writing a single line of code. The agent will be equipped with an SDK and a set of guardrails, and operate more or less like a go-to-market engineer.


